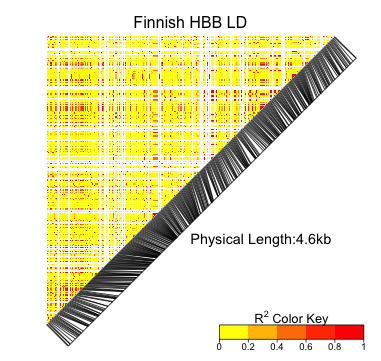
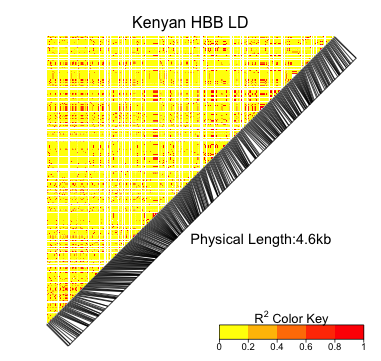
high-order knockout accuracy change:
[0.04639988736460943, 0.04639988736460943, 0.04639988736460943, 0.027510534638317097, 0.19488173720568724, 3.374308469595647, 0.052744375314214054, 0.021825068367524736, 0.08098510601248954, 0.037281014078338615, 0.04639988736460943, 0.04639988736460943, 0.027510534638317097, 0.19488173720568724, 3.374308469595647, 0.052744375314214054, 0.021825068367524736, 0.08098510601248954, 0.037281014078338615, 0.04639988736460943, 0.027510534638317097, 0.19488173720568724, 3.374308469595647, 0.052744375314214054, 0.021825068367524736, 0.08098510601248954, 0.037281014078338615, 0.027510534638317097, 0.19488173720568724, 3.374308469595647, 0.052744375314214054, 0.021825068367524736, 0.08098510601248954, 0.037281014078338615, 0.1843035110784097, 2.8088940414296495, 0.07287416234685118, 0.04626442049646151, 0.11138933160063935, 0.10936076886751422, 3.2698276957628627, 0.21968805385313317, 0.3666712373227057, 0.22230182448790003, 0.1713302152511229, 4.734180187251919, 3.587362501682242, 3.8294607064979944, 3.1624288135366916, 0.058666419199772335, 0.2443440964969703, 0.20717623728584655, 0.12392009172628704, 0.09646807570000782, 0.19132259936976403, 0.04639988736460943, 0.027510534638317097, 0.19488173720568724, 3.374308469595647, 0.052744375314214054, 0.021825068367524736, 0.08098510601248954, 0.037281014078338615, 0.027510534638317097, 0.19488173720568724, 3.374308469595647, 0.052744375314214054, 0.021825068367524736, 0.08098510601248954, 0.037281014078338615, 0.1843035110784097, 2.8088940414296495, 0.07287416234685118, 0.04626442049646151, 0.11138933160063935, 0.10936076886751422, 3.2698276957628627, 0.21968805385313317, 0.3666712373227057, 0.22230182448790003, 0.1713302152511229, 4.734180187251919, 3.587362501682242, 3.8294607064979944, 3.1624288135366916, 0.058666419199772335, 0.2443440964969703, 0.20717623728584655, 0.12392009172628704, 0.09646807570000782, 0.19132259936976403, 0.027510534638317097, 0.19488173720568724, 3.374308469595647, 0.052744375314214054, 0.021825068367524736, 0.08098510601248954, 0.037281014078338615, 0.1843035110784097, 2.8088940414296495, 0.07287416234685118, 0.04626442049646151, 0.11138933160063935, 0.10936076886751422, 3.2698276957628627, 0.21968805385313317, 0.3666712373227057, 0.22230182448790003, 0.1713302152511229, 4.734180187251919, 3.587362501682242, 3.8294607064979944, 3.1624288135366916, 0.058666419199772335, 0.2443440964969703, 0.20717623728584655, 0.12392009172628704, 0.09646807570000782, 0.19132259936976403, 0.1843035110784097, 2.8088940414296495, 0.07287416234685118, 0.04626442049646151, 0.11138933160063935, 0.10936076886751422, 3.2698276957628627, 0.21968805385313317, 0.3666712373227057, 0.22230182448790003, 0.1713302152511229, 4.734180187251919, 3.587362501682242, 3.8294607064979944, 3.1624288135366916, 0.058666419199772335, 0.2443440964969703, 0.20717623728584655, 0.12392009172628704, 0.09646807570000782, 0.19132259936976403, 2.8547430207062945, 0.22634134145111062, 0.4258830698531426, 0.17796891004468307, 0.12885996909805364, 4.139879116486767, 3.101583556579527, 3.192691031955686, 2.7153131343598096, 0.10326163841709324, 0.21587628772912737, 0.23772187707904102, 0.20051989744865395, 0.19039203963900242, 0.2543550890908328, 4.589429408365294, 3.7375721227714562, 3.8310065575323113, 3.0131735230689243, 0.47874715854687366, 0.1147516393373742, 0.3312577684624962, 0.42477877108902184, 0.3489568684626274, 0.18006912643432926, 5.08718343631219, 5.223274698710005, 4.294880209017686, 4.138878833943083, 3.412256736956966, 3.4387810790804547, 0.23199265140118186, 0.2389331534427157, 0.31208246678238183, 0.37878847948599415, 0.027510534638317097, 0.19488173720568724, 3.374308469595647, 0.052744375314214054, 0.021825068367524736, 0.08098510601248954, 0.037281014078338615, 0.1843035110784097, 2.8088940414296495, 0.07287416234685118, 0.04626442049646151, 0.11138933160063935, 0.10936076886751422, 3.2698276957628627, 0.21968805385313317, 0.3666712373227057, 0.22230182448790003, 0.1713302152511229, 4.734180187251919, 3.587362501682242, 3.8294607064979944, 3.1624288135366916, 0.058666419199772335, 0.2443440964969703, 0.20717623728584655, 0.12392009172628704, 0.09646807570000782, 0.19132259936976403, 0.1843035110784097, 2.8088940414296495, 0.07287416234685118, 0.04626442049646151, 0.11138933160063935, 0.10936076886751422, 3.2698276957628627, 0.21968805385313317, 0.3666712373227057, 0.22230182448790003, 0.1713302152511229, 4.734180187251919, 3.587362501682242, 3.8294607064979944, 3.1624288135366916, 0.058666419199772335, 0.2443440964969703, 0.20717623728584655, 0.12392009172628704, 0.09646807570000782, 0.19132259936976403, 2.8547430207062945, 0.22634134145111062, 0.4258830698531426, 0.17796891004468307, 0.12885996909805364, 4.139879116486767, 3.101583556579527, 3.192691031955686, 2.7153131343598096, 0.10326163841709324, 0.21587628772912737, 0.23772187707904102, 0.20051989744865395, 0.19039203963900242, 0.2543550890908328, 4.589429408365294, 3.7375721227714562, 3.8310065575323113, 3.0131735230689243, 0.47874715854687366, 0.1147516393373742, 0.3312577684624962, 0.42477877108902184, 0.3489568684626274, 0.18006912643432926, 5.08718343631219, 5.223274698710005, 4.294880209017686, 4.138878833943083, 3.412256736956966, 3.4387810790804547, 0.23199265140118186, 0.2389331534427157, 0.31208246678238183, 0.37878847948599415, 0.1843035110784097, 2.8088940414296495, 0.07287416234685118, 0.04626442049646151, 0.11138933160063935, 0.10936076886751422, 3.2698276957628627, 0.21968805385313317, 0.3666712373227057, 0.22230182448790003, 0.1713302152511229, 4.734180187251919, 3.587362501682242, 3.8294607064979944, 3.1624288135366916, 0.058666419199772335, 0.2443440964969703, 0.20717623728584655, 0.12392009172628704, 0.09646807570000782, 0.19132259936976403, 2.8547430207062945, 0.22634134145111062, 0.4258830698531426, 0.17796891004468307, 0.12885996909805364, 4.139879116486767, 3.101583556579527, 3.192691031955686, 2.7153131343598096, 0.10326163841709324, 0.21587628772912737, 0.23772187707904102, 0.20051989744865395, 0.19039203963900242, 0.2543550890908328, 4.589429408365294, 3.7375721227714562, 3.8310065575323113, 3.0131735230689243, 0.47874715854687366, 0.1147516393373742, 0.3312577684624962, 0.42477877108902184, 0.3489568684626274, 0.18006912643432926, 5.08718343631219, 5.223274698710005, 4.294880209017686, 4.138878833943083, 3.412256736956966, 3.4387810790804547, 0.23199265140118186, 0.2389331534427157, 0.31208246678238183, 0.37878847948599415, 2.8547430207062945, 0.22634134145111062, 0.4258830698531426, 0.17796891004468307, 0.12885996909805364, 4.139879116486767, 3.101583556579527, 3.192691031955686, 2.7153131343598096, 0.10326163841709324, 0.21587628772912737, 0.23772187707904102, 0.20051989744865395, 0.19039203963900242, 0.2543550890908328, 4.589429408365294, 3.7375721227714562, 3.8310065575323113, 3.0131735230689243, 0.47874715854687366, 0.1147516393373742, 0.3312577684624962, 0.42477877108902184, 0.3489568684626274, 0.18006912643432926, 5.08718343631219, 5.223274698710005, 4.294880209017686, 4.138878833943083, 3.412256736956966, 3.4387810790804547, 0.23199265140118186, 0.2389331534427157, 0.31208246678238183, 0.37878847948599415, 4.011326184333655, 3.3117475583521054, 3.339840921294705, 2.655441854777508, 0.48810310907683174, 0.15497940659520104, 0.3360603418561823, 0.42916747713236525, 0.32766921702108753, 0.05705086328592124, 4.558700492244825, 4.669377151267385, 3.8570187767339146, 3.5944074116594242, 2.912443437564617, 2.9390324634322456, 0.14171135538763302, 0.28671645392682876, 0.2958867779738412, 0.6366051749635133, 5.179024168056652, 5.07305140439398, 4.261627682482974, 4.422894010316348, 3.446866642270577, 3.5197406973039413, 0.21811468689800861, 0.44897167215508205, 0.3011154605226807, 0.3034038331691189, 5.426047095767712, 4.434496848332272, 4.570317689284098, 3.8020605047401324, 0.3434449264755397, 0.1843035110784097, 2.8088940414296495, 0.07287416234685118, 0.04626442049646151, 0.11138933160063935, 0.10936076886751422, 3.2698276957628627, 0.21968805385313317, 0.3666712373227057, 0.22230182448790003, 0.1713302152511229, 4.734180187251919, 3.587362501682242, 3.8294607064979944, 3.1624288135366916, 0.058666419199772335, 0.2443440964969703, 0.20717623728584655, 0.12392009172628704, 0.09646807570000782, 0.19132259936976403, 2.8547430207062945, 0.22634134145111062, 0.4258830698531426, 0.17796891004468307, 0.12885996909805364, 4.139879116486767, 3.101583556579527, 3.192691031955686, 2.7153131343598096, 0.10326163841709324, 0.21587628772912737, 0.23772187707904102, 0.20051989744865395, 0.19039203963900242, 0.2543550890908328, 4.589429408365294, 3.7375721227714562, 3.8310065575323113, 3.0131735230689243, 0.47874715854687366, 0.1147516393373742, 0.3312577684624962, 0.42477877108902184, 0.3489568684626274, 0.18006912643432926, 5.08718343631219, 5.223274698710005, 4.294880209017686, 4.138878833943083, 3.412256736956966, 3.4387810790804547, 0.23199265140118186, 0.2389331534427157, 0.31208246678238183, 0.37878847948599415, 2.8547430207062945, 0.22634134145111062, 0.4258830698531426, 0.17796891004468307, 0.12885996909805364, 4.139879116486767, 3.101583556579527, 3.192691031955686, 2.7153131343598096, 0.10326163841709324, 0.21587628772912737, 0.23772187707904102, 0.20051989744865395, 0.19039203963900242, 0.2543550890908328, 4.589429408365294, 3.7375721227714562, 3.8310065575323113, 3.0131735230689243, 0.47874715854687366, 0.1147516393373742, 0.3312577684624962, 0.42477877108902184, 0.3489568684626274, 0.18006912643432926, 5.08718343631219, 5.223274698710005, 4.294880209017686, 4.138878833943083, 3.412256736956966, 3.4387810790804547, 0.23199265140118186, 0.2389331534427157, 0.31208246678238183, 0.37878847948599415, 4.011326184333655, 3.3117475583521054, 3.339840921294705, 2.655441854777508, 0.48810310907683174, 0.15497940659520104, 0.3360603418561823, 0.42916747713236525, 0.32766921702108753, 0.05705086328592124, 4.558700492244825, 4.669377151267385, 3.8570187767339146, 3.5944074116594242, 2.912443437564617, 2.9390324634322456, 0.14171135538763302, 0.28671645392682876, 0.2958867779738412, 0.6366051749635133, 5.179024168056652, 5.07305140439398, 4.261627682482974, 4.422894010316348, 3.446866642270577, 3.5197406973039413, 0.21811468689800861, 0.44897167215508205, 0.3011154605226807, 0.3034038331691189, 5.426047095767712, 4.434496848332272, 4.570317689284098, 3.8020605047401324, 0.3434449264755397, 2.8547430207062945, 0.22634134145111062, 0.4258830698531426, 0.17796891004468307, 0.12885996909805364, 4.139879116486767, 3.101583556579527, 3.192691031955686, 2.7153131343598096, 0.10326163841709324, 0.21587628772912737, 0.23772187707904102, 0.20051989744865395, 0.19039203963900242, 0.2543550890908328, 4.589429408365294, 3.7375721227714562, 3.8310065575323113, 3.0131735230689243, 0.47874715854687366, 0.1147516393373742, 0.3312577684624962, 0.42477877108902184, 0.3489568684626274, 0.18006912643432926, 5.08718343631219, 5.223274698710005, 4.294880209017686, 4.138878833943083, 3.412256736956966, 3.4387810790804547, 0.23199265140118186, 0.2389331534427157, 0.31208246678238183, 0.37878847948599415, 4.011326184333655, 3.3117475583521054, 3.339840921294705, 2.655441854777508, 0.48810310907683174, 0.15497940659520104, 0.3360603418561823, 0.42916747713236525, 0.32766921702108753, 0.05705086328592124, 4.558700492244825, 4.669377151267385, 3.8570187767339146, 3.5944074116594242, 2.912443437564617, 2.9390324634322456, 0.14171135538763302, 0.28671645392682876, 0.2958867779738412, 0.6366051749635133, 5.179024168056652, 5.07305140439398, 4.261627682482974, 4.422894010316348, 3.446866642270577, 3.5197406973039413, 0.21811468689800861, 0.44897167215508205, 0.3011154605226807, 0.3034038331691189, 5.426047095767712, 4.434496848332272, 4.570317689284098, 3.8020605047401324, 0.3434449264755397, 4.011326184333655, 3.3117475583521054, 3.339840921294705, 2.655441854777508, 0.48810310907683174, 0.15497940659520104, 0.3360603418561823, 0.42916747713236525, 0.32766921702108753, 0.05705086328592124, 4.558700492244825, 4.669377151267385, 3.8570187767339146, 3.5944074116594242, 2.912443437564617, 2.9390324634322456, 0.14171135538763302, 0.28671645392682876, 0.2958867779738412, 0.6366051749635133, 5.179024168056652, 5.07305140439398, 4.261627682482974, 4.422894010316348, 3.446866642270577, 3.5197406973039413, 0.21811468689800861, 0.44897167215508205, 0.3011154605226807, 0.3034038331691189, 5.426047095767712, 4.434496848332272, 4.570317689284098, 3.8020605047401324, 0.3434449264755397, 4.595816747894877, 4.346907651406751, 3.7668426144412477, 3.9010662657712603, 3.006074844714525, 3.083025112948973, 0.2622363171505402, 0.5417426421013278, 0.42989756112238986, 0.2147564552259169, 4.963530222873048, 4.0619534732783436, 4.150392074036729, 3.1149282590369136, 0.6926671256785912, 5.613381572963104, 4.720526925571363, 4.613128077309473, 3.956539323891146, 0.44631103406578276, 4.509252502431731, 2.8547430207062945, 0.22634134145111062, 0.4258830698531426, 0.17796891004468307, 0.12885996909805364, 4.139879116486767, 3.101583556579527, 3.192691031955686, 2.7153131343598096, 0.10326163841709324, 0.21587628772912737, 0.23772187707904102, 0.20051989744865395, 0.19039203963900242, 0.2543550890908328, 4.589429408365294, 3.7375721227714562, 3.8310065575323113, 3.0131735230689243, 0.47874715854687366, 0.1147516393373742, 0.3312577684624962, 0.42477877108902184, 0.3489568684626274, 0.18006912643432926, 5.08718343631219, 5.223274698710005, 4.294880209017686, 4.138878833943083, 3.412256736956966, 3.4387810790804547, 0.23199265140118186, 0.2389331534427157, 0.31208246678238183, 0.37878847948599415, 4.011326184333655, 3.3117475583521054, 3.339840921294705, 2.655441854777508, 0.48810310907683174, 0.15497940659520104, 0.3360603418561823, 0.42916747713236525, 0.32766921702108753, 0.05705086328592124, 4.558700492244825, 4.669377151267385, 3.8570187767339146, 3.5944074116594242, 2.912443437564617, 2.9390324634322456, 0.14171135538763302, 0.28671645392682876, 0.2958867779738412, 0.6366051749635133, 5.179024168056652, 5.07305140439398, 4.261627682482974, 4.422894010316348, 3.446866642270577, 3.5197406973039413, 0.21811468689800861, 0.44897167215508205, 0.3011154605226807, 0.3034038331691189, 5.426047095767712, 4.434496848332272, 4.570317689284098, 3.8020605047401324, 0.3434449264755397, 4.011326184333655, 3.3117475583521054, 3.339840921294705, 2.655441854777508, 0.48810310907683174, 0.15497940659520104, 0.3360603418561823, 0.42916747713236525, 0.32766921702108753, 0.05705086328592124, 4.558700492244825, 4.669377151267385, 3.8570187767339146, 3.5944074116594242, 2.912443437564617, 2.9390324634322456, 0.14171135538763302, 0.28671645392682876, 0.2958867779738412, 0.6366051749635133, 5.179024168056652, 5.07305140439398, 4.261627682482974, 4.422894010316348, 3.446866642270577, 3.5197406973039413, 0.21811468689800861, 0.44897167215508205, 0.3011154605226807, 0.3034038331691189, 5.426047095767712, 4.434496848332272, 4.570317689284098, 3.8020605047401324, 0.3434449264755397, 4.595816747894877, 4.346907651406751, 3.7668426144412477, 3.9010662657712603, 3.006074844714525, 3.083025112948973, 0.2622363171505402, 0.5417426421013278, 0.42989756112238986, 0.2147564552259169, 4.963530222873048, 4.0619534732783436, 4.150392074036729, 3.1149282590369136, 0.6926671256785912, 5.613381572963104, 4.720526925571363, 4.613128077309473, 3.956539323891146, 0.44631103406578276, 4.509252502431731, 4.011326184333655, 3.3117475583521054, 3.339840921294705, 2.655441854777508, 0.48810310907683174, 0.15497940659520104, 0.3360603418561823, 0.42916747713236525, 0.32766921702108753, 0.05705086328592124, 4.558700492244825, 4.669377151267385, 3.8570187767339146, 3.5944074116594242, 2.912443437564617, 2.9390324634322456, 0.14171135538763302, 0.28671645392682876, 0.2958867779738412, 0.6366051749635133, 5.179024168056652, 5.07305140439398, 4.261627682482974, 4.422894010316348, 3.446866642270577, 3.5197406973039413, 0.21811468689800861, 0.44897167215508205, 0.3011154605226807, 0.3034038331691189, 5.426047095767712, 4.434496848332272, 4.570317689284098, 3.8020605047401324, 0.3434449264755397, 4.595816747894877, 4.346907651406751, 3.7668426144412477, 3.9010662657712603, 3.006074844714525, 3.083025112948973, 0.2622363171505402, 0.5417426421013278, 0.42989756112238986, 0.2147564552259169, 4.963530222873048, 4.0619534732783436, 4.150392074036729, 3.1149282590369136, 0.6926671256785912, 5.613381572963104, 4.720526925571363, 4.613128077309473, 3.956539323891146, 0.44631103406578276, 4.509252502431731, 4.595816747894877, 4.346907651406751, 3.7668426144412477, 3.9010662657712603, 3.006074844714525, 3.083025112948973, 0.2622363171505402, 0.5417426421013278, 0.42989756112238986, 0.2147564552259169, 4.963530222873048, 4.0619534732783436, 4.150392074036729, 3.1149282590369136, 0.6926671256785912, 5.613381572963104, 4.720526925571363, 4.613128077309473, 3.956539323891146, 0.44631103406578276, 4.509252502431731, 5.0122864081563305, 4.238077980583448, 4.068178043485734, 3.474812298397164, 0.01389200829499515, 4.16032057025792, 4.911473800911488, 4.011326184333655, 3.3117475583521054, 3.339840921294705, 2.655441854777508, 0.48810310907683174, 0.15497940659520104, 0.3360603418561823, 0.42916747713236525, 0.32766921702108753, 0.05705086328592124, 4.558700492244825, 4.669377151267385, 3.8570187767339146, 3.5944074116594242, 2.912443437564617, 2.9390324634322456, 0.14171135538763302, 0.28671645392682876, 0.2958867779738412, 0.6366051749635133, 5.179024168056652, 5.07305140439398, 4.261627682482974, 4.422894010316348, 3.446866642270577, 3.5197406973039413, 0.21811468689800861, 0.44897167215508205, 0.3011154605226807, 0.3034038331691189, 5.426047095767712, 4.434496848332272, 4.570317689284098, 3.8020605047401324, 0.3434449264755397, 4.595816747894877, 4.346907651406751, 3.7668426144412477, 3.9010662657712603, 3.006074844714525, 3.083025112948973, 0.2622363171505402, 0.5417426421013278, 0.42989756112238986, 0.2147564552259169, 4.963530222873048, 4.0619534732783436, 4.150392074036729, 3.1149282590369136, 0.6926671256785912, 5.613381572963104, 4.720526925571363, 4.613128077309473, 3.956539323891146, 0.44631103406578276, 4.509252502431731, 4.595816747894877, 4.346907651406751, 3.7668426144412477, 3.9010662657712603, 3.006074844714525, 3.083025112948973, 0.2622363171505402, 0.5417426421013278, 0.42989756112238986, 0.2147564552259169, 4.963530222873048, 4.0619534732783436, 4.150392074036729, 3.1149282590369136, 0.6926671256785912, 5.613381572963104, 4.720526925571363, 4.613128077309473, 3.956539323891146, 0.44631103406578276, 4.509252502431731, 5.0122864081563305, 4.238077980583448, 4.068178043485734, 3.474812298397164, 0.01389200829499515, 4.16032057025792, 4.911473800911488, 4.595816747894877, 4.346907651406751, 3.7668426144412477, 3.9010662657712603, 3.006074844714525, 3.083025112948973, 0.2622363171505402, 0.5417426421013278, 0.42989756112238986, 0.2147564552259169, 4.963530222873048, 4.0619534732783436, 4.150392074036729, 3.1149282590369136, 0.6926671256785912, 5.613381572963104, 4.720526925571363, 4.613128077309473, 3.956539323891146, 0.44631103406578276, 4.509252502431731, 5.0122864081563305, 4.238077980583448, 4.068178043485734, 3.474812298397164, 0.01389200829499515, 4.16032057025792, 4.911473800911488, 5.0122864081563305, 4.238077980583448, 4.068178043485734, 3.474812298397164, 0.01389200829499515, 4.16032057025792, 4.911473800911488, 4.479078899831331, 4.595816747894877, 4.346907651406751, 3.7668426144412477, 3.9010662657712603, 3.006074844714525, 3.083025112948973, 0.2622363171505402, 0.5417426421013278, 0.42989756112238986, 0.2147564552259169, 4.963530222873048, 4.0619534732783436, 4.150392074036729, 3.1149282590369136, 0.6926671256785912, 5.613381572963104, 4.720526925571363, 4.613128077309473, 3.956539323891146, 0.44631103406578276, 4.509252502431731, 5.0122864081563305, 4.238077980583448, 4.068178043485734, 3.474812298397164, 0.01389200829499515, 4.16032057025792, 4.911473800911488, 5.0122864081563305, 4.238077980583448, 4.068178043485734, 3.474812298397164, 0.01389200829499515, 4.16032057025792, 4.911473800911488, 4.479078899831331, 5.0122864081563305, 4.238077980583448, 4.068178043485734, 3.474812298397164, 0.01389200829499515, 4.16032057025792, 4.911473800911488, 4.479078899831331, 4.479078899831331, 5.0122864081563305, 4.238077980583448, 4.068178043485734, 3.474812298397164, 0.01389200829499515, 4.16032057025792, 4.911473800911488, 4.479078899831331, 4.479078899831331, 4.479078899831331]
index:
[[0], [1], [2], [3], [4], [5], [6], [7], [8], [9], [0, 1], [0, 2], [0, 3], [0, 4], [0, 5], [0, 6], [0, 7], [0, 8], [0, 9], [1, 2], [1, 3], [1, 4], [1, 5], [1, 6], [1, 7], [1, 8], [1, 9], [2, 3], [2, 4], [2, 5], [2, 6], [2, 7], [2, 8], [2, 9], [3, 4], [3, 5], [3, 6], [3, 7], [3, 8], [3, 9], [4, 5], [4, 6], [4, 7], [4, 8], [4, 9], [5, 6], [5, 7], [5, 8], [5, 9], [6, 7], [6, 8], [6, 9], [7, 8], [7, 9], [8, 9], [0, 1, 2], [0, 1, 3], [0, 1, 4], [0, 1, 5], [0, 1, 6], [0, 1, 7], [0, 1, 8], [0, 1, 9], [0, 2, 3], [0, 2, 4], [0, 2, 5], [0, 2, 6], [0, 2, 7], [0, 2, 8], [0, 2, 9], [0, 3, 4], [0, 3, 5], [0, 3, 6], [0, 3, 7], [0, 3, 8], [0, 3, 9], [0, 4, 5], [0, 4, 6], [0, 4, 7], [0, 4, 8], [0, 4, 9], [0, 5, 6], [0, 5, 7], [0, 5, 8], [0, 5, 9], [0, 6, 7], [0, 6, 8], [0, 6, 9], [0, 7, 8], [0, 7, 9], [0, 8, 9], [1, 2, 3], [1, 2, 4], [1, 2, 5], [1, 2, 6], [1, 2, 7], [1, 2, 8], [1, 2, 9], [1, 3, 4], [1, 3, 5], [1, 3, 6], [1, 3, 7], [1, 3, 8], [1, 3, 9], [1, 4, 5], [1, 4, 6], [1, 4, 7], [1, 4, 8], [1, 4, 9], [1, 5, 6], [1, 5, 7], [1, 5, 8], [1, 5, 9], [1, 6, 7], [1, 6, 8], [1, 6, 9], [1, 7, 8], [1, 7, 9], [1, 8, 9], [2, 3, 4], [2, 3, 5], [2, 3, 6], [2, 3, 7], [2, 3, 8], [2, 3, 9], [2, 4, 5], [2, 4, 6], [2, 4, 7], [2, 4, 8], [2, 4, 9], [2, 5, 6], [2, 5, 7], [2, 5, 8], [2, 5, 9], [2, 6, 7], [2, 6, 8], [2, 6, 9], [2, 7, 8], [2, 7, 9], [2, 8, 9], [3, 4, 5], [3, 4, 6], [3, 4, 7], [3, 4, 8], [3, 4, 9], [3, 5, 6], [3, 5, 7], [3, 5, 8], [3, 5, 9], [3, 6, 7], [3, 6, 8], [3, 6, 9], [3, 7, 8], [3, 7, 9], [3, 8, 9], [4, 5, 6], [4, 5, 7], [4, 5, 8], [4, 5, 9], [4, 6, 7], [4, 6, 8], [4, 6, 9], [4, 7, 8], [4, 7, 9], [4, 8, 9], [5, 6, 7], [5, 6, 8], [5, 6, 9], [5, 7, 8], [5, 7, 9], [5, 8, 9], [6, 7, 8], [6, 7, 9], [6, 8, 9], [7, 8, 9], [0, 1, 2, 3], [0, 1, 2, 4], [0, 1, 2, 5], [0, 1, 2, 6], [0, 1, 2, 7], [0, 1, 2, 8], [0, 1, 2, 9], [0, 1, 3, 4], [0, 1, 3, 5], [0, 1, 3, 6], [0, 1, 3, 7], [0, 1, 3, 8], [0, 1, 3, 9], [0, 1, 4, 5], [0, 1, 4, 6], [0, 1, 4, 7], [0, 1, 4, 8], [0, 1, 4, 9], [0, 1, 5, 6], [0, 1, 5, 7], [0, 1, 5, 8], [0, 1, 5, 9], [0, 1, 6, 7], [0, 1, 6, 8], [0, 1, 6, 9], [0, 1, 7, 8], [0, 1, 7, 9], [0, 1, 8, 9], [0, 2, 3, 4], [0, 2, 3, 5], [0, 2, 3, 6], [0, 2, 3, 7], [0, 2, 3, 8], [0, 2, 3, 9], [0, 2, 4, 5], [0, 2, 4, 6], [0, 2, 4, 7], [0, 2, 4, 8], [0, 2, 4, 9], [0, 2, 5, 6], [0, 2, 5, 7], [0, 2, 5, 8], [0, 2, 5, 9], [0, 2, 6, 7], [0, 2, 6, 8], [0, 2, 6, 9], [0, 2, 7, 8], [0, 2, 7, 9], [0, 2, 8, 9], [0, 3, 4, 5], [0, 3, 4, 6], [0, 3, 4, 7], [0, 3, 4, 8], [0, 3, 4, 9], [0, 3, 5, 6], [0, 3, 5, 7], [0, 3, 5, 8], [0, 3, 5, 9], [0, 3, 6, 7], [0, 3, 6, 8], [0, 3, 6, 9], [0, 3, 7, 8], [0, 3, 7, 9], [0, 3, 8, 9], [0, 4, 5, 6], [0, 4, 5, 7], [0, 4, 5, 8], [0, 4, 5, 9], [0, 4, 6, 7], [0, 4, 6, 8], [0, 4, 6, 9], [0, 4, 7, 8], [0, 4, 7, 9], [0, 4, 8, 9], [0, 5, 6, 7], [0, 5, 6, 8], [0, 5, 6, 9], [0, 5, 7, 8], [0, 5, 7, 9], [0, 5, 8, 9], [0, 6, 7, 8], [0, 6, 7, 9], [0, 6, 8, 9], [0, 7, 8, 9], [1, 2, 3, 4], [1, 2, 3, 5], [1, 2, 3, 6], [1, 2, 3, 7], [1, 2, 3, 8], [1, 2, 3, 9], [1, 2, 4, 5], [1, 2, 4, 6], [1, 2, 4, 7], [1, 2, 4, 8], [1, 2, 4, 9], [1, 2, 5, 6], [1, 2, 5, 7], [1, 2, 5, 8], [1, 2, 5, 9], [1, 2, 6, 7], [1, 2, 6, 8], [1, 2, 6, 9], [1, 2, 7, 8], [1, 2, 7, 9], [1, 2, 8, 9], [1, 3, 4, 5], [1, 3, 4, 6], [1, 3, 4, 7], [1, 3, 4, 8], [1, 3, 4, 9], [1, 3, 5, 6], [1, 3, 5, 7], [1, 3, 5, 8], [1, 3, 5, 9], [1, 3, 6, 7], [1, 3, 6, 8], [1, 3, 6, 9], [1, 3, 7, 8], [1, 3, 7, 9], [1, 3, 8, 9], [1, 4, 5, 6], [1, 4, 5, 7], [1, 4, 5, 8], [1, 4, 5, 9], [1, 4, 6, 7], [1, 4, 6, 8], [1, 4, 6, 9], [1, 4, 7, 8], [1, 4, 7, 9], [1, 4, 8, 9], [1, 5, 6, 7], [1, 5, 6, 8], [1, 5, 6, 9], [1, 5, 7, 8], [1, 5, 7, 9], [1, 5, 8, 9], [1, 6, 7, 8], [1, 6, 7, 9], [1, 6, 8, 9], [1, 7, 8, 9], [2, 3, 4, 5], [2, 3, 4, 6], [2, 3, 4, 7], [2, 3, 4, 8], [2, 3, 4, 9], [2, 3, 5, 6], [2, 3, 5, 7], [2, 3, 5, 8], [2, 3, 5, 9], [2, 3, 6, 7], [2, 3, 6, 8], [2, 3, 6, 9], [2, 3, 7, 8], [2, 3, 7, 9], [2, 3, 8, 9], [2, 4, 5, 6], [2, 4, 5, 7], [2, 4, 5, 8], [2, 4, 5, 9], [2, 4, 6, 7], [2, 4, 6, 8], [2, 4, 6, 9], [2, 4, 7, 8], [2, 4, 7, 9], [2, 4, 8, 9], [2, 5, 6, 7], [2, 5, 6, 8], [2, 5, 6, 9], [2, 5, 7, 8], [2, 5, 7, 9], [2, 5, 8, 9], [2, 6, 7, 8], [2, 6, 7, 9], [2, 6, 8, 9], [2, 7, 8, 9], [3, 4, 5, 6], [3, 4, 5, 7], [3, 4, 5, 8], [3, 4, 5, 9], [3, 4, 6, 7], [3, 4, 6, 8], [3, 4, 6, 9], [3, 4, 7, 8], [3, 4, 7, 9], [3, 4, 8, 9], [3, 5, 6, 7], [3, 5, 6, 8], [3, 5, 6, 9], [3, 5, 7, 8], [3, 5, 7, 9], [3, 5, 8, 9], [3, 6, 7, 8], [3, 6, 7, 9], [3, 6, 8, 9], [3, 7, 8, 9], [4, 5, 6, 7], [4, 5, 6, 8], [4, 5, 6, 9], [4, 5, 7, 8], [4, 5, 7, 9], [4, 5, 8, 9], [4, 6, 7, 8], [4, 6, 7, 9], [4, 6, 8, 9], [4, 7, 8, 9], [5, 6, 7, 8], [5, 6, 7, 9], [5, 6, 8, 9], [5, 7, 8, 9], [6, 7, 8, 9], [0, 1, 2, 3, 4], [0, 1, 2, 3, 5], [0, 1, 2, 3, 6], [0, 1, 2, 3, 7], [0, 1, 2, 3, 8], [0, 1, 2, 3, 9], [0, 1, 2, 4, 5], [0, 1, 2, 4, 6], [0, 1, 2, 4, 7], [0, 1, 2, 4, 8], [0, 1, 2, 4, 9], [0, 1, 2, 5, 6], [0, 1, 2, 5, 7], [0, 1, 2, 5, 8], [0, 1, 2, 5, 9], [0, 1, 2, 6, 7], [0, 1, 2, 6, 8], [0, 1, 2, 6, 9], [0, 1, 2, 7, 8], [0, 1, 2, 7, 9], [0, 1, 2, 8, 9], [0, 1, 3, 4, 5], [0, 1, 3, 4, 6], [0, 1, 3, 4, 7], [0, 1, 3, 4, 8], [0, 1, 3, 4, 9], [0, 1, 3, 5, 6], [0, 1, 3, 5, 7], [0, 1, 3, 5, 8], [0, 1, 3, 5, 9], [0, 1, 3, 6, 7], [0, 1, 3, 6, 8], [0, 1, 3, 6, 9], [0, 1, 3, 7, 8], [0, 1, 3, 7, 9], [0, 1, 3, 8, 9], [0, 1, 4, 5, 6], [0, 1, 4, 5, 7], [0, 1, 4, 5, 8], [0, 1, 4, 5, 9], [0, 1, 4, 6, 7], [0, 1, 4, 6, 8], [0, 1, 4, 6, 9], [0, 1, 4, 7, 8], [0, 1, 4, 7, 9], [0, 1, 4, 8, 9], [0, 1, 5, 6, 7], [0, 1, 5, 6, 8], [0, 1, 5, 6, 9], [0, 1, 5, 7, 8], [0, 1, 5, 7, 9], [0, 1, 5, 8, 9], [0, 1, 6, 7, 8], [0, 1, 6, 7, 9], [0, 1, 6, 8, 9], [0, 1, 7, 8, 9], [0, 2, 3, 4, 5], [0, 2, 3, 4, 6], [0, 2, 3, 4, 7], [0, 2, 3, 4, 8], [0, 2, 3, 4, 9], [0, 2, 3, 5, 6], [0, 2, 3, 5, 7], [0, 2, 3, 5, 8], [0, 2, 3, 5, 9], [0, 2, 3, 6, 7], [0, 2, 3, 6, 8], [0, 2, 3, 6, 9], [0, 2, 3, 7, 8], [0, 2, 3, 7, 9], [0, 2, 3, 8, 9], [0, 2, 4, 5, 6], [0, 2, 4, 5, 7], [0, 2, 4, 5, 8], [0, 2, 4, 5, 9], [0, 2, 4, 6, 7], [0, 2, 4, 6, 8], [0, 2, 4, 6, 9], [0, 2, 4, 7, 8], [0, 2, 4, 7, 9], [0, 2, 4, 8, 9], [0, 2, 5, 6, 7], [0, 2, 5, 6, 8], [0, 2, 5, 6, 9], [0, 2, 5, 7, 8], [0, 2, 5, 7, 9], [0, 2, 5, 8, 9], [0, 2, 6, 7, 8], [0, 2, 6, 7, 9], [0, 2, 6, 8, 9], [0, 2, 7, 8, 9], [0, 3, 4, 5, 6], [0, 3, 4, 5, 7], [0, 3, 4, 5, 8], [0, 3, 4, 5, 9], [0, 3, 4, 6, 7], [0, 3, 4, 6, 8], [0, 3, 4, 6, 9], [0, 3, 4, 7, 8], [0, 3, 4, 7, 9], [0, 3, 4, 8, 9], [0, 3, 5, 6, 7], [0, 3, 5, 6, 8], [0, 3, 5, 6, 9], [0, 3, 5, 7, 8], [0, 3, 5, 7, 9], [0, 3, 5, 8, 9], [0, 3, 6, 7, 8], [0, 3, 6, 7, 9], [0, 3, 6, 8, 9], [0, 3, 7, 8, 9], [0, 4, 5, 6, 7], [0, 4, 5, 6, 8], [0, 4, 5, 6, 9], [0, 4, 5, 7, 8], [0, 4, 5, 7, 9], [0, 4, 5, 8, 9], [0, 4, 6, 7, 8], [0, 4, 6, 7, 9], [0, 4, 6, 8, 9], [0, 4, 7, 8, 9], [0, 5, 6, 7, 8], [0, 5, 6, 7, 9], [0, 5, 6, 8, 9], [0, 5, 7, 8, 9], [0, 6, 7, 8, 9], [1, 2, 3, 4, 5], [1, 2, 3, 4, 6], [1, 2, 3, 4, 7], [1, 2, 3, 4, 8], [1, 2, 3, 4, 9], [1, 2, 3, 5, 6], [1, 2, 3, 5, 7], [1, 2, 3, 5, 8], [1, 2, 3, 5, 9], [1, 2, 3, 6, 7], [1, 2, 3, 6, 8], [1, 2, 3, 6, 9], [1, 2, 3, 7, 8], [1, 2, 3, 7, 9], [1, 2, 3, 8, 9], [1, 2, 4, 5, 6], [1, 2, 4, 5, 7], [1, 2, 4, 5, 8], [1, 2, 4, 5, 9], [1, 2, 4, 6, 7], [1, 2, 4, 6, 8], [1, 2, 4, 6, 9], [1, 2, 4, 7, 8], [1, 2, 4, 7, 9], [1, 2, 4, 8, 9], [1, 2, 5, 6, 7], [1, 2, 5, 6, 8], [1, 2, 5, 6, 9], [1, 2, 5, 7, 8], [1, 2, 5, 7, 9], [1, 2, 5, 8, 9], [1, 2, 6, 7, 8], [1, 2, 6, 7, 9], [1, 2, 6, 8, 9], [1, 2, 7, 8, 9], [1, 3, 4, 5, 6], [1, 3, 4, 5, 7], [1, 3, 4, 5, 8], [1, 3, 4, 5, 9], [1, 3, 4, 6, 7], [1, 3, 4, 6, 8], [1, 3, 4, 6, 9], [1, 3, 4, 7, 8], [1, 3, 4, 7, 9], [1, 3, 4, 8, 9], [1, 3, 5, 6, 7], [1, 3, 5, 6, 8], [1, 3, 5, 6, 9], [1, 3, 5, 7, 8], [1, 3, 5, 7, 9], [1, 3, 5, 8, 9], [1, 3, 6, 7, 8], [1, 3, 6, 7, 9], [1, 3, 6, 8, 9], [1, 3, 7, 8, 9], [1, 4, 5, 6, 7], [1, 4, 5, 6, 8], [1, 4, 5, 6, 9], [1, 4, 5, 7, 8], [1, 4, 5, 7, 9], [1, 4, 5, 8, 9], [1, 4, 6, 7, 8], [1, 4, 6, 7, 9], [1, 4, 6, 8, 9], [1, 4, 7, 8, 9], [1, 5, 6, 7, 8], [1, 5, 6, 7, 9], [1, 5, 6, 8, 9], [1, 5, 7, 8, 9], [1, 6, 7, 8, 9], [2, 3, 4, 5, 6], [2, 3, 4, 5, 7], [2, 3, 4, 5, 8], [2, 3, 4, 5, 9], [2, 3, 4, 6, 7], [2, 3, 4, 6, 8], [2, 3, 4, 6, 9], [2, 3, 4, 7, 8], [2, 3, 4, 7, 9], [2, 3, 4, 8, 9], [2, 3, 5, 6, 7], [2, 3, 5, 6, 8], [2, 3, 5, 6, 9], [2, 3, 5, 7, 8], [2, 3, 5, 7, 9], [2, 3, 5, 8, 9], [2, 3, 6, 7, 8], [2, 3, 6, 7, 9], [2, 3, 6, 8, 9], [2, 3, 7, 8, 9], [2, 4, 5, 6, 7], [2, 4, 5, 6, 8], [2, 4, 5, 6, 9], [2, 4, 5, 7, 8], [2, 4, 5, 7, 9], [2, 4, 5, 8, 9], [2, 4, 6, 7, 8], [2, 4, 6, 7, 9], [2, 4, 6, 8, 9], [2, 4, 7, 8, 9], [2, 5, 6, 7, 8], [2, 5, 6, 7, 9], [2, 5, 6, 8, 9], [2, 5, 7, 8, 9], [2, 6, 7, 8, 9], [3, 4, 5, 6, 7], [3, 4, 5, 6, 8], [3, 4, 5, 6, 9], [3, 4, 5, 7, 8], [3, 4, 5, 7, 9], [3, 4, 5, 8, 9], [3, 4, 6, 7, 8], [3, 4, 6, 7, 9], [3, 4, 6, 8, 9], [3, 4, 7, 8, 9], [3, 5, 6, 7, 8], [3, 5, 6, 7, 9], [3, 5, 6, 8, 9], [3, 5, 7, 8, 9], [3, 6, 7, 8, 9], [4, 5, 6, 7, 8], [4, 5, 6, 7, 9], [4, 5, 6, 8, 9], [4, 5, 7, 8, 9], [4, 6, 7, 8, 9], [5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5], [0, 1, 2, 3, 4, 6], [0, 1, 2, 3, 4, 7], [0, 1, 2, 3, 4, 8], [0, 1, 2, 3, 4, 9], [0, 1, 2, 3, 5, 6], [0, 1, 2, 3, 5, 7], [0, 1, 2, 3, 5, 8], [0, 1, 2, 3, 5, 9], [0, 1, 2, 3, 6, 7], [0, 1, 2, 3, 6, 8], [0, 1, 2, 3, 6, 9], [0, 1, 2, 3, 7, 8], [0, 1, 2, 3, 7, 9], [0, 1, 2, 3, 8, 9], [0, 1, 2, 4, 5, 6], [0, 1, 2, 4, 5, 7], [0, 1, 2, 4, 5, 8], [0, 1, 2, 4, 5, 9], [0, 1, 2, 4, 6, 7], [0, 1, 2, 4, 6, 8], [0, 1, 2, 4, 6, 9], [0, 1, 2, 4, 7, 8], [0, 1, 2, 4, 7, 9], [0, 1, 2, 4, 8, 9], [0, 1, 2, 5, 6, 7], [0, 1, 2, 5, 6, 8], [0, 1, 2, 5, 6, 9], [0, 1, 2, 5, 7, 8], [0, 1, 2, 5, 7, 9], [0, 1, 2, 5, 8, 9], [0, 1, 2, 6, 7, 8], [0, 1, 2, 6, 7, 9], [0, 1, 2, 6, 8, 9], [0, 1, 2, 7, 8, 9], [0, 1, 3, 4, 5, 6], [0, 1, 3, 4, 5, 7], [0, 1, 3, 4, 5, 8], [0, 1, 3, 4, 5, 9], [0, 1, 3, 4, 6, 7], [0, 1, 3, 4, 6, 8], [0, 1, 3, 4, 6, 9], [0, 1, 3, 4, 7, 8], [0, 1, 3, 4, 7, 9], [0, 1, 3, 4, 8, 9], [0, 1, 3, 5, 6, 7], [0, 1, 3, 5, 6, 8], [0, 1, 3, 5, 6, 9], [0, 1, 3, 5, 7, 8], [0, 1, 3, 5, 7, 9], [0, 1, 3, 5, 8, 9], [0, 1, 3, 6, 7, 8], [0, 1, 3, 6, 7, 9], [0, 1, 3, 6, 8, 9], [0, 1, 3, 7, 8, 9], [0, 1, 4, 5, 6, 7], [0, 1, 4, 5, 6, 8], [0, 1, 4, 5, 6, 9], [0, 1, 4, 5, 7, 8], [0, 1, 4, 5, 7, 9], [0, 1, 4, 5, 8, 9], [0, 1, 4, 6, 7, 8], [0, 1, 4, 6, 7, 9], [0, 1, 4, 6, 8, 9], [0, 1, 4, 7, 8, 9], [0, 1, 5, 6, 7, 8], [0, 1, 5, 6, 7, 9], [0, 1, 5, 6, 8, 9], [0, 1, 5, 7, 8, 9], [0, 1, 6, 7, 8, 9], [0, 2, 3, 4, 5, 6], [0, 2, 3, 4, 5, 7], [0, 2, 3, 4, 5, 8], [0, 2, 3, 4, 5, 9], [0, 2, 3, 4, 6, 7], [0, 2, 3, 4, 6, 8], [0, 2, 3, 4, 6, 9], [0, 2, 3, 4, 7, 8], [0, 2, 3, 4, 7, 9], [0, 2, 3, 4, 8, 9], [0, 2, 3, 5, 6, 7], [0, 2, 3, 5, 6, 8], [0, 2, 3, 5, 6, 9], [0, 2, 3, 5, 7, 8], [0, 2, 3, 5, 7, 9], [0, 2, 3, 5, 8, 9], [0, 2, 3, 6, 7, 8], [0, 2, 3, 6, 7, 9], [0, 2, 3, 6, 8, 9], [0, 2, 3, 7, 8, 9], [0, 2, 4, 5, 6, 7], [0, 2, 4, 5, 6, 8], [0, 2, 4, 5, 6, 9], [0, 2, 4, 5, 7, 8], [0, 2, 4, 5, 7, 9], [0, 2, 4, 5, 8, 9], [0, 2, 4, 6, 7, 8], [0, 2, 4, 6, 7, 9], [0, 2, 4, 6, 8, 9], [0, 2, 4, 7, 8, 9], [0, 2, 5, 6, 7, 8], [0, 2, 5, 6, 7, 9], [0, 2, 5, 6, 8, 9], [0, 2, 5, 7, 8, 9], [0, 2, 6, 7, 8, 9], [0, 3, 4, 5, 6, 7], [0, 3, 4, 5, 6, 8], [0, 3, 4, 5, 6, 9], [0, 3, 4, 5, 7, 8], [0, 3, 4, 5, 7, 9], [0, 3, 4, 5, 8, 9], [0, 3, 4, 6, 7, 8], [0, 3, 4, 6, 7, 9], [0, 3, 4, 6, 8, 9], [0, 3, 4, 7, 8, 9], [0, 3, 5, 6, 7, 8], [0, 3, 5, 6, 7, 9], [0, 3, 5, 6, 8, 9], [0, 3, 5, 7, 8, 9], [0, 3, 6, 7, 8, 9], [0, 4, 5, 6, 7, 8], [0, 4, 5, 6, 7, 9], [0, 4, 5, 6, 8, 9], [0, 4, 5, 7, 8, 9], [0, 4, 6, 7, 8, 9], [0, 5, 6, 7, 8, 9], [1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 7], [1, 2, 3, 4, 5, 8], [1, 2, 3, 4, 5, 9], [1, 2, 3, 4, 6, 7], [1, 2, 3, 4, 6, 8], [1, 2, 3, 4, 6, 9], [1, 2, 3, 4, 7, 8], [1, 2, 3, 4, 7, 9], [1, 2, 3, 4, 8, 9], [1, 2, 3, 5, 6, 7], [1, 2, 3, 5, 6, 8], [1, 2, 3, 5, 6, 9], [1, 2, 3, 5, 7, 8], [1, 2, 3, 5, 7, 9], [1, 2, 3, 5, 8, 9], [1, 2, 3, 6, 7, 8], [1, 2, 3, 6, 7, 9], [1, 2, 3, 6, 8, 9], [1, 2, 3, 7, 8, 9], [1, 2, 4, 5, 6, 7], [1, 2, 4, 5, 6, 8], [1, 2, 4, 5, 6, 9], [1, 2, 4, 5, 7, 8], [1, 2, 4, 5, 7, 9], [1, 2, 4, 5, 8, 9], [1, 2, 4, 6, 7, 8], [1, 2, 4, 6, 7, 9], [1, 2, 4, 6, 8, 9], [1, 2, 4, 7, 8, 9], [1, 2, 5, 6, 7, 8], [1, 2, 5, 6, 7, 9], [1, 2, 5, 6, 8, 9], [1, 2, 5, 7, 8, 9], [1, 2, 6, 7, 8, 9], [1, 3, 4, 5, 6, 7], [1, 3, 4, 5, 6, 8], [1, 3, 4, 5, 6, 9], [1, 3, 4, 5, 7, 8], [1, 3, 4, 5, 7, 9], [1, 3, 4, 5, 8, 9], [1, 3, 4, 6, 7, 8], [1, 3, 4, 6, 7, 9], [1, 3, 4, 6, 8, 9], [1, 3, 4, 7, 8, 9], [1, 3, 5, 6, 7, 8], [1, 3, 5, 6, 7, 9], [1, 3, 5, 6, 8, 9], [1, 3, 5, 7, 8, 9], [1, 3, 6, 7, 8, 9], [1, 4, 5, 6, 7, 8], [1, 4, 5, 6, 7, 9], [1, 4, 5, 6, 8, 9], [1, 4, 5, 7, 8, 9], [1, 4, 6, 7, 8, 9], [1, 5, 6, 7, 8, 9], [2, 3, 4, 5, 6, 7], [2, 3, 4, 5, 6, 8], [2, 3, 4, 5, 6, 9], [2, 3, 4, 5, 7, 8], [2, 3, 4, 5, 7, 9], [2, 3, 4, 5, 8, 9], [2, 3, 4, 6, 7, 8], [2, 3, 4, 6, 7, 9], [2, 3, 4, 6, 8, 9], [2, 3, 4, 7, 8, 9], [2, 3, 5, 6, 7, 8], [2, 3, 5, 6, 7, 9], [2, 3, 5, 6, 8, 9], [2, 3, 5, 7, 8, 9], [2, 3, 6, 7, 8, 9], [2, 4, 5, 6, 7, 8], [2, 4, 5, 6, 7, 9], [2, 4, 5, 6, 8, 9], [2, 4, 5, 7, 8, 9], [2, 4, 6, 7, 8, 9], [2, 5, 6, 7, 8, 9], [3, 4, 5, 6, 7, 8], [3, 4, 5, 6, 7, 9], [3, 4, 5, 6, 8, 9], [3, 4, 5, 7, 8, 9], [3, 4, 6, 7, 8, 9], [3, 5, 6, 7, 8, 9], [4, 5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 4, 5, 7], [0, 1, 2, 3, 4, 5, 8], [0, 1, 2, 3, 4, 5, 9], [0, 1, 2, 3, 4, 6, 7], [0, 1, 2, 3, 4, 6, 8], [0, 1, 2, 3, 4, 6, 9], [0, 1, 2, 3, 4, 7, 8], [0, 1, 2, 3, 4, 7, 9], [0, 1, 2, 3, 4, 8, 9], [0, 1, 2, 3, 5, 6, 7], [0, 1, 2, 3, 5, 6, 8], [0, 1, 2, 3, 5, 6, 9], [0, 1, 2, 3, 5, 7, 8], [0, 1, 2, 3, 5, 7, 9], [0, 1, 2, 3, 5, 8, 9], [0, 1, 2, 3, 6, 7, 8], [0, 1, 2, 3, 6, 7, 9], [0, 1, 2, 3, 6, 8, 9], [0, 1, 2, 3, 7, 8, 9], [0, 1, 2, 4, 5, 6, 7], [0, 1, 2, 4, 5, 6, 8], [0, 1, 2, 4, 5, 6, 9], [0, 1, 2, 4, 5, 7, 8], [0, 1, 2, 4, 5, 7, 9], [0, 1, 2, 4, 5, 8, 9], [0, 1, 2, 4, 6, 7, 8], [0, 1, 2, 4, 6, 7, 9], [0, 1, 2, 4, 6, 8, 9], [0, 1, 2, 4, 7, 8, 9], [0, 1, 2, 5, 6, 7, 8], [0, 1, 2, 5, 6, 7, 9], [0, 1, 2, 5, 6, 8, 9], [0, 1, 2, 5, 7, 8, 9], [0, 1, 2, 6, 7, 8, 9], [0, 1, 3, 4, 5, 6, 7], [0, 1, 3, 4, 5, 6, 8], [0, 1, 3, 4, 5, 6, 9], [0, 1, 3, 4, 5, 7, 8], [0, 1, 3, 4, 5, 7, 9], [0, 1, 3, 4, 5, 8, 9], [0, 1, 3, 4, 6, 7, 8], [0, 1, 3, 4, 6, 7, 9], [0, 1, 3, 4, 6, 8, 9], [0, 1, 3, 4, 7, 8, 9], [0, 1, 3, 5, 6, 7, 8], [0, 1, 3, 5, 6, 7, 9], [0, 1, 3, 5, 6, 8, 9], [0, 1, 3, 5, 7, 8, 9], [0, 1, 3, 6, 7, 8, 9], [0, 1, 4, 5, 6, 7, 8], [0, 1, 4, 5, 6, 7, 9], [0, 1, 4, 5, 6, 8, 9], [0, 1, 4, 5, 7, 8, 9], [0, 1, 4, 6, 7, 8, 9], [0, 1, 5, 6, 7, 8, 9], [0, 2, 3, 4, 5, 6, 7], [0, 2, 3, 4, 5, 6, 8], [0, 2, 3, 4, 5, 6, 9], [0, 2, 3, 4, 5, 7, 8], [0, 2, 3, 4, 5, 7, 9], [0, 2, 3, 4, 5, 8, 9], [0, 2, 3, 4, 6, 7, 8], [0, 2, 3, 4, 6, 7, 9], [0, 2, 3, 4, 6, 8, 9], [0, 2, 3, 4, 7, 8, 9], [0, 2, 3, 5, 6, 7, 8], [0, 2, 3, 5, 6, 7, 9], [0, 2, 3, 5, 6, 8, 9], [0, 2, 3, 5, 7, 8, 9], [0, 2, 3, 6, 7, 8, 9], [0, 2, 4, 5, 6, 7, 8], [0, 2, 4, 5, 6, 7, 9], [0, 2, 4, 5, 6, 8, 9], [0, 2, 4, 5, 7, 8, 9], [0, 2, 4, 6, 7, 8, 9], [0, 2, 5, 6, 7, 8, 9], [0, 3, 4, 5, 6, 7, 8], [0, 3, 4, 5, 6, 7, 9], [0, 3, 4, 5, 6, 8, 9], [0, 3, 4, 5, 7, 8, 9], [0, 3, 4, 6, 7, 8, 9], [0, 3, 5, 6, 7, 8, 9], [0, 4, 5, 6, 7, 8, 9], [1, 2, 3, 4, 5, 6, 7], [1, 2, 3, 4, 5, 6, 8], [1, 2, 3, 4, 5, 6, 9], [1, 2, 3, 4, 5, 7, 8], [1, 2, 3, 4, 5, 7, 9], [1, 2, 3, 4, 5, 8, 9], [1, 2, 3, 4, 6, 7, 8], [1, 2, 3, 4, 6, 7, 9], [1, 2, 3, 4, 6, 8, 9], [1, 2, 3, 4, 7, 8, 9], [1, 2, 3, 5, 6, 7, 8], [1, 2, 3, 5, 6, 7, 9], [1, 2, 3, 5, 6, 8, 9], [1, 2, 3, 5, 7, 8, 9], [1, 2, 3, 6, 7, 8, 9], [1, 2, 4, 5, 6, 7, 8], [1, 2, 4, 5, 6, 7, 9], [1, 2, 4, 5, 6, 8, 9], [1, 2, 4, 5, 7, 8, 9], [1, 2, 4, 6, 7, 8, 9], [1, 2, 5, 6, 7, 8, 9], [1, 3, 4, 5, 6, 7, 8], [1, 3, 4, 5, 6, 7, 9], [1, 3, 4, 5, 6, 8, 9], [1, 3, 4, 5, 7, 8, 9], [1, 3, 4, 6, 7, 8, 9], [1, 3, 5, 6, 7, 8, 9], [1, 4, 5, 6, 7, 8, 9], [2, 3, 4, 5, 6, 7, 8], [2, 3, 4, 5, 6, 7, 9], [2, 3, 4, 5, 6, 8, 9], [2, 3, 4, 5, 7, 8, 9], [2, 3, 4, 6, 7, 8, 9], [2, 3, 5, 6, 7, 8, 9], [2, 4, 5, 6, 7, 8, 9], [3, 4, 5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5, 6, 7], [0, 1, 2, 3, 4, 5, 6, 8], [0, 1, 2, 3, 4, 5, 6, 9], [0, 1, 2, 3, 4, 5, 7, 8], [0, 1, 2, 3, 4, 5, 7, 9], [0, 1, 2, 3, 4, 5, 8, 9], [0, 1, 2, 3, 4, 6, 7, 8], [0, 1, 2, 3, 4, 6, 7, 9], [0, 1, 2, 3, 4, 6, 8, 9], [0, 1, 2, 3, 4, 7, 8, 9], [0, 1, 2, 3, 5, 6, 7, 8], [0, 1, 2, 3, 5, 6, 7, 9], [0, 1, 2, 3, 5, 6, 8, 9], [0, 1, 2, 3, 5, 7, 8, 9], [0, 1, 2, 3, 6, 7, 8, 9], [0, 1, 2, 4, 5, 6, 7, 8], [0, 1, 2, 4, 5, 6, 7, 9], [0, 1, 2, 4, 5, 6, 8, 9], [0, 1, 2, 4, 5, 7, 8, 9], [0, 1, 2, 4, 6, 7, 8, 9], [0, 1, 2, 5, 6, 7, 8, 9], [0, 1, 3, 4, 5, 6, 7, 8], [0, 1, 3, 4, 5, 6, 7, 9], [0, 1, 3, 4, 5, 6, 8, 9], [0, 1, 3, 4, 5, 7, 8, 9], [0, 1, 3, 4, 6, 7, 8, 9], [0, 1, 3, 5, 6, 7, 8, 9], [0, 1, 4, 5, 6, 7, 8, 9], [0, 2, 3, 4, 5, 6, 7, 8], [0, 2, 3, 4, 5, 6, 7, 9], [0, 2, 3, 4, 5, 6, 8, 9], [0, 2, 3, 4, 5, 7, 8, 9], [0, 2, 3, 4, 6, 7, 8, 9], [0, 2, 3, 5, 6, 7, 8, 9], [0, 2, 4, 5, 6, 7, 8, 9], [0, 3, 4, 5, 6, 7, 8, 9], [1, 2, 3, 4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7, 9], [1, 2, 3, 4, 5, 6, 8, 9], [1, 2, 3, 4, 5, 7, 8, 9], [1, 2, 3, 4, 6, 7, 8, 9], [1, 2, 3, 5, 6, 7, 8, 9], [1, 2, 4, 5, 6, 7, 8, 9], [1, 3, 4, 5, 6, 7, 8, 9], [2, 3, 4, 5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5, 6, 7, 8], [0, 1, 2, 3, 4, 5, 6, 7, 9], [0, 1, 2, 3, 4, 5, 6, 8, 9], [0, 1, 2, 3, 4, 5, 7, 8, 9], [0, 1, 2, 3, 4, 6, 7, 8, 9], [0, 1, 2, 3, 5, 6, 7, 8, 9], [0, 1, 2, 4, 5, 6, 7, 8, 9], [0, 1, 3, 4, 5, 6, 7, 8, 9], [0, 2, 3, 4, 5, 6, 7, 8, 9], [1, 2, 3, 4, 5, 6, 7, 8, 9]]
![Iterative Knockout for Feature Importance in Neural Networks [Python] [Keras]](https://piperwrites95180714.files.wordpress.com/2018/05/system-2660914_1920.jpg?w=1200)